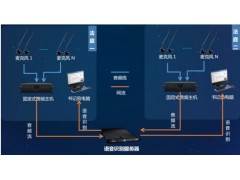
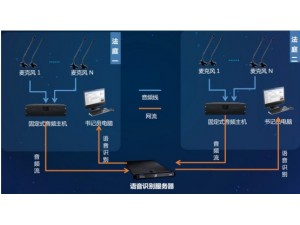


系统组成
庭审语音识别包括: 庭审语音识别系统(PC)、信息数字音频处理系统、语音识别服务器。
信息数字音频处理系统可对每个话筒进行独立处理后输出,经语音识别服务器识别转换成文字后推送到语音转写系统(PC),实现将文字与身份捆绑呈现。
庭审语音识别系统(PC)
智能庭审语音识别系统,功能如下:
●角色分离:自动区分发言人的角色,系统对发言内容进行语音转写时,识别结果自动对应到相应的角色(如:审判长、原告、被告)。
●实时转写:在各种庭审过程中,对参与庭审的各个角色的语音进行实时转写,以文字形式实时推 送到书记员电脑上。书记员可实时校对、编辑,完毕即可生成电子庭审笔录。
●语音识别功能开启和关闭:再庭审过程中,语音识别开关可以随时开启/关闭。
●重点标记:因现场嘈杂、争吵激烈、方言口音较重等因素导致语音识别效果错误率偏高,法庭书记员又来不及马上修改的地方,可在此处划线标记。待庭审结束后,方便书记员进行文字校正。
●识别文本的保存与查看:识别生成的文字会自动保存在书记员的电脑中,可下载及查看笔录信息。
●案件统计查询:可统计查询庭审案件的数量及其某个分类案件的数量和具体信息。
4.2语音识别服务器
语音识别引擎,负责将庭审的语音转成文字。具体功能如下:
●语音识别:语音识别引擎将法庭内实时的音频流转换成为文字。并且将文字发送给前端应用系统。










